Understanding Latent Dirichlet Allocation
Natural Language Processing

In the month of July, we are going to start a new theme: natural language processing. Last month, when we were going through generative AI, we touched on some text generation, which is an overlapping area with natural language processing. In July, we will dive deeper into this topic.
Latent Dirichlet Allocation is a statistical model often used in natural language processing to extract the main topics from a document or a set of documents. This helps in organizing, understanding, and summarizing large amounts of textual information.
In the below example, we will walk through the summarization of “Pride and Prejudice” by Jane Austen. The full text is available at this link.
We start by downloading the text file using Python’s requests library, and specify the URL where the text file is located and sent an HTTP GET request to download it. The text of the book is then stored in the ‘text’ variable.

Once the ‘text’ variable is defined, we will then perform several text preprocessing steps:
Tokenize text into individual sentences using ‘nltk.sent_tokenize’
Convert each sentence into a list of words
Remove any non-alphabetic words
Convert all words into lower case
Remove any stopwords - for an explanation of stopwords, please refer to the word cloud tutorial I have done earlier in the year
Lemmatize words - reduce inflected or derived words to their word stem or root form, (e.g. running to run)

Once the text is preprocessed, we create a dictionary object from the tokens. The dictionary object is a mapping between words and their integer IDs. We also create a corpus, which is a list of vectors equal to the number of documents. Each document is represented by a series f tuples, and each tuple represents a word and its frequency in the document.

The Latent Dirichlet Allocation model is trained on the corpus. This is where we specify the number of topics we want to model to identify, provide the dictionary, and specify the number of passes through the corpus during training.

Finally, we print out the topics. Each topic is represented as a string in the following format.
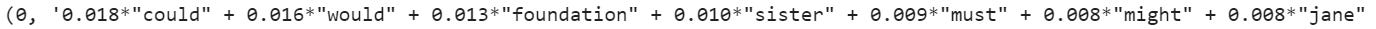
In the above output, the numbers associated with each word represent the weight or importance of the word for that topic. So for the above output, the words “could”, “would”, “fountain”, and “sister” are particularly important.
As demonstrated above, LDA makes a highly valuable tool in data mining and information retrieval from text data. Below is the full codebook for the above exercise:

AIQ by Nick Polson and James Scott
The Associated Press has started using an algorithm that can write a passable racap of a baseball game from a box score, which it currently uses for faraway college games with no reporter present. The system has even learned to insert sports-writing cliches; it just takes the data one game at a time. Data scientists at Salesforce recently developed a similar program that can accurately summarize long articles to help the company’s employees digest news reports more quickly. And as two academics who’ve suffered the slings and arrows of peer review, we were not at all surprised to learn of an algorithm created by researchers at the University of Trieste - one that wrote fake peer reviews good enough to fool real journal editors.
CodeChat
CodeChat will continue this month and to be held on July 28 at 5pm EST. The topic is going to be on natural language processing and their uses, joiners’ perspectives, as well as any questions you may have related to coding. You may sign up here for a meeting reminder or the meeting link is here if you would like to join directly.
Feedback
The Substackers’ message board is a place where you can share your coding journey with me, so that we can exchange ideas and become better together.
Please open the message board and share with me your thoughts!