
One of the key challenges for fraud detection is that popular models on the market would usually require known history of fraud and non-fraud data in order to make predictions about new data. Isolation Forest solves this problem as it is an unsupervised machine learning model, which does not require labeled data to make predictions on new data.
Isolation Forest identifies anomalies based on the structure of the dataset itself. It does this by isolating each observation in a tree-like structure, randomly selecting features and split values to isolate each observation from others. Anomalies are those observations that require fewer splits to be isolated.
And due to the unsupervised nature of isolation forest, it can be used to identify new and previously unknown types of fraud or other anomalies.
Having labeled data in the isolation forest environment can help in assessing the accuracy of Isolation Forest predictions and in fine-tuning model parameters such as the contamination rate. Yet, the isolation forest model when operating without labeled data can nonetheless be effective at detecting anomalies in large datasets, including financial data used in forensic accounting.
In the example below, we’ll create a dataset of randomly generated bank transactions, with date, amount and type (credit or debit). We’ll also introduce three anomalies into the dataset by modifying the transaction amounts of three transactions.

Next, we’ll use isolation forest to detect the anomalies in the dataset:

In the code above, we set the number of trees in the forest to 100 in the n_estimators parameter, and the expected fraction of outliers in the dataset to 0.7% in the contamination parameter. We then use the predict method to generate anomaly scores for each observation in the dataset.
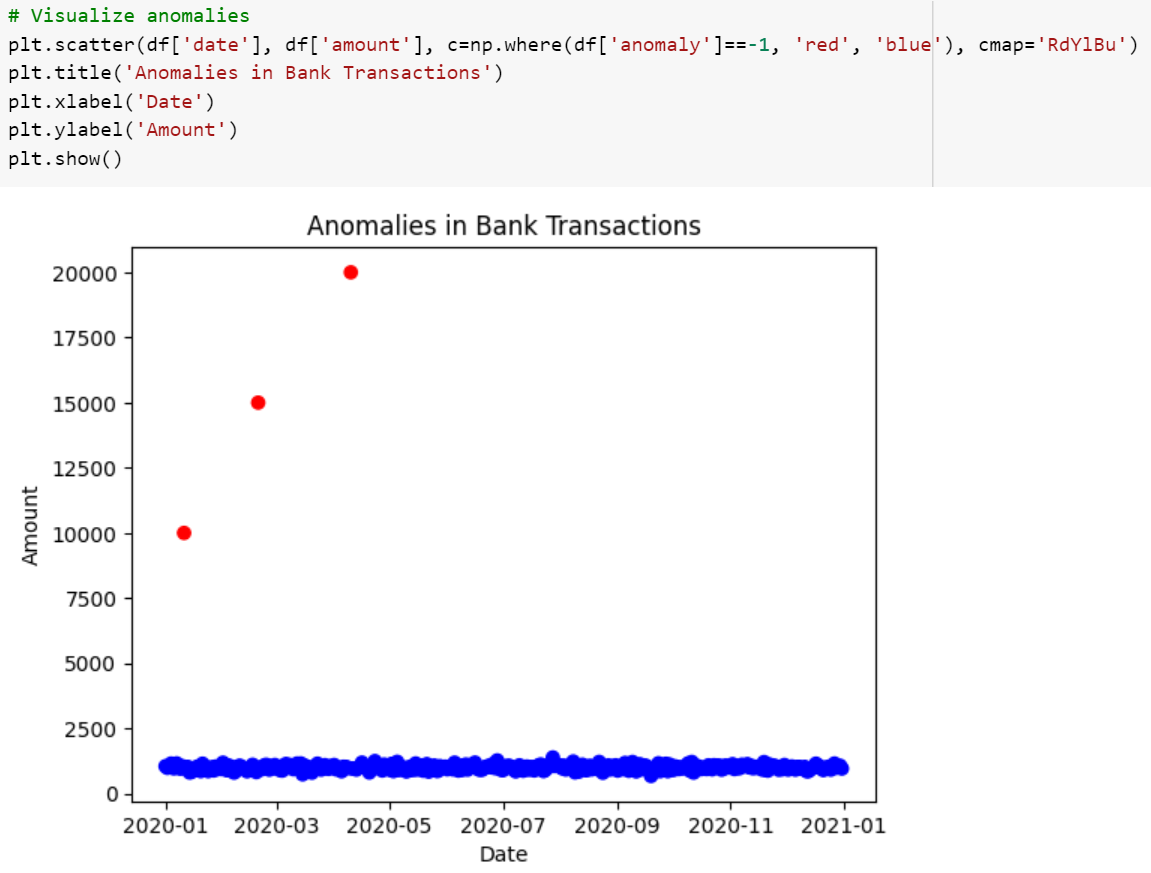
Once the model is fit into our data, we are ready to plot three anomaly data points against the non-anomaly data points.
We could also use the below code to visualize the first decision tree in the isolation forest that was used to arrive at the above result.

Below is the full codebook for this exercise:

CodeChat
I also hold code talks on Google Meet on the last Friday of every month at 5:00 p.m. The topic for the next chat is going to be on Digesting Decision Trees in Python as well as a deeper dive on isolation forest and any questions you may have related to coding. You may sign up here for a meeting reminder or the meeting link is here if you would like to join directly.
Feedback
The Substackers’ message board is a place where you can share your coding journey with me, so that we can exchange ideas and become better together.
Please open the message board and share with me your thoughts!